Unicode for Arabists
Update 2025-12-27 — Typo fixes.
This post is based on a presentation gave in the Digital Area Studies seminar at University of Oslo, Department of Culture Studies and Oriental Languages, May 30, 2022.
This post is a practically oriented introduction to Unicode for people regularly writing in or about Arabic. In Arabic digital text, a lot of work is done under the hood to rearrange and connect letters for correct display. Quite often, however, this system produces undesired results, such as punctuation jumping around or words appearing in the incorrect order. Understanding these problems, and solving them, often requires some basic understanding of Unicode in order to engage with the text on the level of digital encoding, rather than on the level of visual display.
Vim: Throughout this post, I have included boxes with tips on how to do things in Vim/Neovim, my editor of choice. If you are not a Vim user, these boxes can be ignored and I hope they will not be too distracting.
Contents
- Unicode basics
- Directionality
- Arabic combining characters
- Quranic orthography
- Letter binding control
- Transcription
- Conclusion
- References
Unicode basics
Unicode has been the standard for digital text encoding since the early 2000s. It provides one coherent system for encoding virtually all forms of written language in current use (as well as those not in use) and replaces the plethora of different encoding system that were used previously. If you are typing letters other than those in the English alphabet, the text is almost guaranteed to be encoded in Unicode.
For a more detailed yet accessible explanation of Unicode, see What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text. I also highly recommended having a look at The Unicode Standard (2019), the official documentation. It is a highly readable and accessible document, even for a non-specialist. I recommend reading or skimming sections 1, Introduction and 2&, General structure (around 70 pages), which give a good general understanding of the system on a conceptual level, and then reading the section on the specific language you are interested in.
From ASCII to Unicode
The Unicode standard for text encoding replaced the various extensions of ASCII (American Standard Code for Information Interchange) that had been used since its creation in 1963. ASCII encodes 128 characters: the upper- and lowercase Latin letters used in English, digits, basic punctuation, various non-printable control characters (that for our purposes can be ignored), as well as some mathematical and other symbols. These 128 characters have come to form the backbone of computer text. Programming languages only use these characters, for example
On the most basic level, computers store information in binary form as ones and zeroes. Any ASCII character can be expressed as a series of seven ones and zeroes, seven bits. In the table, below, the three bits on the top row shows the first three bits of character and the bits in the leftmost column show the last four bits. The first three bits can more conveniently be expressed as the digits 0-7. The last four bits can combine in 16 different ways. Rather than labeling these combinations as numbers 1–16, we label them with hexadecimals, from 0–F (like the normal decimal system of 0–9 but extended with A-F to get a total of sixteen, A=11, B=12, etc.). This hexadecimal system will be important later.
| 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 | ||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 0000 | 0 | NUL | DLE | space | 0 | @ | P | p | |
| 0001 | 1 | SOH | DC1 | ! | 1 | A | Q | a | q |
| 0010 | 2 | STX | DC2 | ” | 2 | B | R | b | r |
| 0011 | 3 | ETX | DC3 | # | 3 | C | S | c | s |
| 0100 | 4 | EOT | DC4 | $ | 4 | D | T | d | t |
| 0101 | 5 | ENQ | NAK | % | 5 | E | U | e | u |
| 0110 | 6 | ACK | SYN | & | 6 | F | V | f | v |
| 0111 | 7 | BEL | ETB | ’ | 7 | G | W | g | w |
| 1000 | 8 | BS | CAN | ( | 8 | H | X | h | x |
| 1001 | 9 | HT | EM | ) | 9 | I | Y | i | y |
| 1010 | A | LF | SUB | * | : | J | Z | j | z |
| 1011 | B | VT | ESC | + | ; | K | [ | k | { |
| 1100 | C | FF | FS | , | < | L | \ | l | |
| 1101 | D | CR | GS | - | = | M | ] | m | } |
| 1110 | E | SO | RS | . | > | N | ^ | n | ~ |
| 1111 | F | SI | US | / | ? | O | _ | o | DEL |
ASCII, as the name implies, was developed as an American system. It is a very efficient way to store text digitally—if you only need to write text in English, that is. To be able to write non-English letters, people started to device extensions of ASCII to allow for more characters to be included. Most of these extensions used an additional eighth bit, doubling the amount of code points to 256. Imagine the table above twice next to one another. The old ASCII characters were typically retained in positions 0–128, as above, with the new positions 129-256 being used for new characters. For example, The Multinational Character Set extends ASCII to include letters required in many European languages, and ISCII extends ASCII to write various Indic languages.
The problem with these extensions was that there was soon a number of different standards floating around, and you needed to know when opening a file in what standard it was encoded, otherwise the characters would be jumbled and incomprehensible. If a text was written in the Indian ISCII and decoded with the Multinational Character Set, the bit sequence 1111010 would be displayed as § rather than the indented उ, and similar things would happen to all characters in the file. Opening text files with all characters jumbled used to be quite a common experience. And, of course, writing in several languages in the same text was quite complicated. Overall, multilingual digital text was a bit of a mess.
Enter Unicode. The idea behind Unicode is to create a scheme for character encoding in which all languages are represented on an even keel in one and the same scheme. The ASCII inventory is neat in that it is has a very small and carefully selected inventory of 128 code points, expressed in a mere seven bits, giving 2⁷ (128) code points. In Unicode, by contrast, each code points is at least sixteen bits, giving 2¹⁶ (65,536) code points, but they have variable length and can be up to 32 bits. In total Unicode has 1,114,112 code points. That is over a million different characters can be encoded. This is a lot. It is more than enough space to encode all characters from all written languages that have ever been in use. As of 2021 (Unicode v.14), 144,697 of these code points are actually assigned to characters. The biggest chunk of these, 92,865 code points, are assigned to Chinese characters. And there is lots of space to spare for future expansions. Crucially, Unicode incorporates ASCII in that the first 128 code points of Unicode are identical to ASCII, so that any text written in ASCII is also readable with Unicode encoding
Unicode currently encodes 159 scripts. Note that scripts are not the same as languages. For example, Swedish and English both use the same Latin script, and Arabic and Farsi use the same Arabic script, or slightly different sets of characters from the same script. The number of languages fully represented in Unicode is therefor far higher than the number of scripts. Indeed, I dare you to find a language that cannot be written in Unicode. In addition to languages of the normal sort, a large number of other sign-systems are covered: forms of musical notion, emojis, astrological and alchemical symbols, typographical ornaments, and what have you. Here is a small tasting, just to give some sense of the breadth of things covered:
- A
- Æ
- 我 (some random Chinese character)
- 𐎄 (Ugarit letter delta)
- ﷺ (Arabic ligature Peace be upon him.)
- 𓀍 (Egyptian hieroglyph A011)
- 😼
- ᚍ (letter ngedal from the Ogham writing system used in Medieval Welsh inscriptions)
- 𐩣 (Old South Arabian letter men)
- ⤴
- ᭷ (Balinese musical symbol, right-hand closed tak)
- ༗ (Tibetan astrological sign sgra gcan)
To familiarize yourself with the Unicode world, and to get some sense of its vastness, it is useful to try and casually explore the Unicode inventory. This is a good place to start. On Mac, if you have enabled Show keyboard and emoji viewers in menu bar in the keyboard settings, you can brows the symbols in Show Emoji & Symbols in that menu. On Windows, you can find a similar functionality under System Tools/Symbol Table.
Vim: With the excellent unicode.vim plugin you can do :UnicodeTable to open the entire Unicode inventory as a massive table in plain text to browse through at your convenience.
Unicode design principles
As explained above, any given character from any script has a unique code point, essentially its binary sequence. Most characters consist of 16 bits (16 ones and zeroes), and every set of four bits can be expressed with one hexadecimal number. A code point in Unicode, which references a character, can therefore be express by four hexadecimals. For example, the letter Æ has the code point 00C6. This is preceded by U+ to indicate that this number is referring to a Unicode code point: U+00C6. The Arabic letter ج has the code point U+0626. Having access to these code points comes in handy, as we will see below.
A Unicode text (as well as text in other coding schemes) is thus a series of numbers, normally expressed in hexadecimals, that each reference a character. When the computer reads this in order to display it on screen, it looks up matches to those numbers in the font you are using and displays these matches as human readable text. Naturally, no font has has all these 1,114,112 characters represented. If the file contains a character that is not represented in the font you are using, the computer will instead show a replacement character, often �. Some software will look for the character in other fonts available in the system, and, if found, display that one character in this other font. MS Word does this, for example. While this does show the character, the result is often note very pleasing.
In Unicode, each character (each code point) is associated with a set of properties that determine, among other things, how the character interact with other characters. These properties are not stored in the text file itself (which is just a list of ones and zeroes representing letters) but is references in a separate database. The most important of these properties for our purposes are:
- Name: an English descriptive name that is unique to that character, typically including the name of the script. This name is by convention in all ASCII uppercase letters. The name of Æ, for example, is LATIN CAPITAL LETTER AE.
-
Category: whether the character is punctuation, letter, digit, upper or lower case, a control character, etc.
The latter, control character, is a particularly important category for our purposes. These are characters that have no visual appearance and take up no horizontal space. They are thus invisible. As shown below, you may want to be able to manipulate them, which can be tricky in commonly used word processors.
-
Writing direction: most commonly left-to-right (LTR), right-to-left (RTL), or neutral.
- Combining or non-combining: whether the character graphically combines with previous characters, as is the case for diacritics and Arabic vowel-signs.
We well return to these properties below.
Typing Unicode
The true power of Unicode is that it gives you access to some 100,000 characters in one unified framework. However, no (practically useful) keyboard has 100,000 keys, and you only ever need a very small subset of all these characters, even in complex multilingual text.
There are three basic ways to access these characters in order to type or otherwise insert them in a file:
-
With the keyboard. This is, of course, the most basic and everyday way to enter characters into a file. Every key on the keyboard is assigned a Unicode code point associated with a character. Which character is assigned to which key is essentially arbitrary, allowing for different keyboard layouts to be used for different languages and purposes on the same physical keyboard. When using a Swedish layout, some keys will produce different characters then when using an American layout. This method, however, only provides access to a small set of characters (those that can fit on the keyboard) and typically only from one language at the time. Often this is all you need.
-
Manual selection. There are many programs that allow you to browse through or search the Unicode inventory for a character that you can then copy or otherwise insert into a document. Most operating systems ship with applications that do this (see above). A simple, low-tech way to do this is to do an internet search for Unicode and the name of the character you are looking for and then copy and paste the character from the browser.
Vim: With the unicode.vim plugin, you can type part of the name of Unicode character and while still in insert mode do Ctrl+x Ctrl+z to get a list of characters with a name that match that string. One of these can then be selected and inserted.
-
By code-point. Many applications allow you to do some keyboard shortcut in combination with the hexadecimal code-point to insert a character. Windows, for example, has a nice feature where you can type out the hexadecimal code in a document, e.g., 1F63C, highlight this string, and then do Alt+x to convert the string to the respective Unicode character (😼 CAT FACE WITH A WRY SMILE).
Vim: CTRL-v followed by u and then the hexadecimal code point in insert mode inserts the character.
It is also very useful to be able to easily identify a character that you come across in a file. There is, however, no built-in way of easily doing this in the common OSs as far as I know.
Vim: ga in normal mode displays information on the character under the cursor.
Directionality
Arabists often find themselves writing bidirectional text, for example a text in English with a few words in the Arabic script. This can be a real hassle because the software that displays the text typically tries to reorder letters you type, that is, it reorders letters to display the Arabic parts RTL while the English parts remain LTR. It does not always get this right, or it does it in a way you’d not expect. If you are regularity working with bidirectional text, it is worth taking the time to understand how this works, so you can control and manipulate it.
Digital text is stored as a simple long list of characters (including spaces, line breaks, paragraph switches, etc.). These characters only have a certain order but no inherent direction. If this list contains letters that are all meant to be read in the same direction, say LTR, the computer can just list all the characters on the screen in in that same direction. If the text contains text meant to be read in different directions, e.g., English LTR and Arabic RTL, there are two options for how this may be displayed on the screen: logical order and visual order.
The logical order is the most basic (but less common) way to display bidirectional text. This is where the characters are simply spewed out in the order in which they as they are stored in the file. You can think of this as the order in which letters are typed. This can be in either direction, either
left-to-right
Hello, hello. اسمي اندرياس. Hello again.
or right-to-left
Hello, hello. اسمي اندرياس. Hello again.
This is, clearly, not how the text is intended to be read by humans. Either the Arabic or the English is incorrectly displayed. Nevertheless, displaying text in this way often makes editing much more convenient.
Most software displaying bidirectional text will instead rearrange letters to display it in the visual order, that is, how it is intended to be read by humans. Here, the computer uses the directionality property for each character specified in Unicode to try to rearrange the characters for human consumption. The exact way this is done is quite complex as it tries to account for punctuation, word boundaries, etc., as explained in the Unicode Bidirectional Algorithm (which I have tired, and failed, to fully understand). The same line as above rearranged with this algorithm looks like this:
Hello, hello. اسمي اندرياس. Hello again.
Letters are now reorder for both scripts to be displayed in their visually correct direction (which is not their order in the file). Your word processor, or in this case your browser, does this automatically. (In order to prevent this rearranging in the previous examples I inserted the control characters LEFT-TO-RIGHT OVERRIDE (U+202D) and RIGHT-TO-LEFT OVERRIDE (U+202E) at the start of the line to force a specific consisted display direction.)
This reordering often requires some manual tweaking, most commonly to deal with punctuation. In the visually reordered example above, you may have noticed that the period associate with the Arabic segment is to its right, rather than at the end of the segment to its left. The period and most other forms of punctuation have a directionality property set to neutral, meaning that they adapt to the main directionality of the paragraph, in this case is LTR. The rearranging mechanism, in effect, sees a series of Arabic letters, rearranges these to be RTL, then sees the period and places it after the Arabic segment as a LTR character. Punctuation jumping around seemingly uncontrollably is one of the most common problems when typing in Arabic.
You can control the placement of characters with neutral directionality with the control characters
- LEFT-TO-RIGHT EMBEDDING (U+202a)
- RIGHT-TO-LEFT EMBEDDING (U+202b)
- POP DIRECTIONAL FORMATTING (U+202C)
The first two introduce an embedded segment that is to be displayed in LTR or RTL, and the latter ends this segment, going back to whatever directionality is the main one of the paragraph. The following example is the same line as above but with RIGHT-LEFT EMBEDDING just before the first Arabic word اسمي and POP DIRECTIONAL FORMATTING just after the second dot:
Hello, hello. اسمي اندرياس. Hello again.
Note how your browser now places the period in accordance with the Arabic visual ordering. If this same line is displayed in an editor that shows control characters and displays the line in logical order, it looks something like this:
Hello, hello. <202b>اسمي اندرياس.<202c> Hello again.
Displaying text like this is very helpful when editing bidirectional text in that you can see everything going on under the hood and don’t have to wrestle with the computer rearranging the text.
Vim: See a previous post on how to work with bidirectionally displayed in logical order in Vim.
Arabic combining characters
A class of Unicode characters that are of particular importance for Arabists is the combining character class. These are characters that
a) take up no horizontal space, and
b) modify or adds to the preceding character.
Arabic vowel signs (fatḥa, ḍamma, kasra, etc.) and letter diacritics used in linguistic transcription (ḥ, š, etc.) are of this class. Combining characters essentially stack on the preceding character.
Unicode has no restrictions on how combining characters can be combined with one another or with non-combining characters (typically a letter) from any script. This means that you can do silly things such as ḍ̣̣͑͑͑, a d with three COMBINING LEFT RING ABOVE and three COMBINING DOT BELOW, have an Arabic letter with a bunch of fatḥas and kasras تََََََِِِِِِِ, or do something more creative: ( ▀ ͜͞ʖ▀). Since the combining characters are encoded as separate characters, even though they do not appear as such, hitting Backspace with the cursor after a letter with a diacritic will only remove the diacritic, the last character before the cursor in the logical order. (This may differ between applications.)
Combining characters, by their nature, are not meant to be displayed in isolation without a letter to serve as their base. If you need show them isolation for purposes of demonstration, the convention is to use ◌ DOTTED CIRCLE (U+25CC) as a placeholder letter. A lone fatḥa is thus displayed like this: ◌َ. (Personally, I don’t like the look of this for Arabic vowel diacritics and prefer to use the Arabic taṭwīl character as a placeholder letter: ـَ, ـِ, ـّ, etc.)
Vowel diacritics (taškīl)
The combining characters that are used in modern typography (taškīl, vowel diacritics) are accessible with the Shift-layer of standard Arabic keyboard layouts. The basic ones are
- ◌ً U+064B ARABIC FATHATAN
- ◌ٌ U+064C ARABIC DAMMATAN
- ◌ٍ U+064D ARABIC KASRATAN
- ◌َ U+064E ARABIC FATHA
- ◌ُ U+064F ARABIC DAMMA
- ◌ِ U+0650 ARABIC KASRA
- ◌ّ U+0651 ARABIC SHADDA
- ◌ْ U+0652 ARABIC SUKUN
So, for example, ب directly followed by ◌َ will show up as بَ, both occupying the same horizontal space. An effect of this is that you cannot place the cursors between the letter and the diacritic and hit Backspace to erase only the letter, nor can you highlight the diacritic without also highlighting the letter, and vice versa. Editing vowel diacritic thus takes some getting used to. Furthermore, the letter and the diacritic must be directly adjacent to show up correctly. This is why you cannot, for example, show a letter and its diacritic in different colors. The (typically invisible) code that ends the color marking segment for the letter would have to go between the letter (ب) and the following diacritic (◌َ), breaking this sequence. Such effects, having different font features of for a letter and its diacritic, can therefore only be achieved in very complex and roundabout ways and is beyond the capabilities of most software.
Dotted letters
Arabic vowel diacritics should not be confused with the dots used to separate letters (ʾiʿjām), and the two are treated very differently in Unicode. The Arabic dotted letters are, of course, their own characters (ت U+062A, etc.), not combinations of two characters, as are letters with vowel diacritics.
However, Unicode does provide dotless forms of dotted letter shapes, e.g., ٮ (ARABIC LETTER DOTLESS BEH U+066E). This is useful for transcribing historical texts where letter dots are used inconsistently or not at all. It is also useful for pedagogical purposes. These dotless characters make it possible to show, for example, how the word فبقى ‘and he stayed’ is written before dots are added: ڡٮٯى. There are also characters for writing the letter-dots in isolation, e.g., ﮴\ (ARABIC SYMBOL TWO DOTS ABOVE U+FBB4). These are, however, not combining characters and cannot be used to with the dotless forms to “reconstruct” the dotted letter.
Enclosing marks
A nice, if somewhat obscure, feature in Arabic Unicode is the characters used for traditional Arabic typesetting aya numbers, page numbers, years, etc. These are enclosing combining marks: they enclose any Arabic digits directly following them. There are five of these:
- U+0600 ARABIC NUMBER SIGN
- U+0601 ARABIC SIGN SANAH
- U+0602 ARABIC FOOTNOTE MARKER
- U+0603 ARABIC SIGN SAFHA
- U+06DD ARABIC END OF AYAH
Below they are written with and without a space between the enclosing mark and the following digits.
٣٤ ٣٤ ٣٤ ٣٤ ٣٤ ٣٤ ٣٤ ٣٤ ٣٤ ٣٤
(This enclosing may not show up properly in your browser, depending on your font setup. This page tries to show these examples, as well as the Quranic examples below, in the Amiri font. If this is unsuccessful, some characters may not appear in their intended shape. As a last resort, you could always copy lines form this page to a word processor and play around with different Arabic fonts until you find one that can display them properly.)
Quranic orthography
The Quran has a number of orthographic features that are not used in other texts. The ARABIC END OF AYA character above is an example of this. For these characters, Unicode has got you covered. To achieve correct Quranic orthography, you do, however, need to dig a little deeper into the Arabic section of the Unicode inventory, beyond what is found on the regular Arabic keyboard layout. Many Arabic fonts lack glyphs for these characters, and you may need a specialized or advanced font to display them.
Consider the following two examples:
أَنَّ ٱللهَ بَرِىٓءࣱ مِّنَ ٱلۡمشۡرِكِينَ وَرَسُولُهُ
إِنَّمَا يَخۡشَى ٱللهَ مِنۡ عِبَادِهِ ٱلۡعُلَمَـٰۤؤُاْ
(For a real-life use of these examples, see Hallberg 2016: 73.)
Note how
- the sukūn does not have the normal circular form of modern typography but the open form used in the Quran
- the double ḍamma in بَرِىٓءࣱ is two visually separated signs
- there is a small alif with madda on top of a letter mīm in ٱلۡعُلَمَـٰۤؤُاْ
All these specialized characters can be inserted with reference to their code points or by manual lookup. There is a whole bunch of such Quran-specific characters in Unicode. Unfortunately, they are a bit spread out in the inventory and do not have names that explicitly mentions the Quran, so it is a bit difficult to locate them all. These are the ones I have identified:
| ◌ࣰ | U+08F0 | ARABIC OPEN FATHATAN |
| ◌ࣱ | U+08F1 | ARABIC OPEN DAMMATAN |
| ◌ࣲ | U+08F2 | ARABIC OPEN KASRATAN |
| ◌ࣿ | U+08FF | ARABIC MARK SIDEWAYS NOON GHUNNA |
| ◌٘ | U+0658 | ARABIC MARK NOON GHUNNA |
| ۖ◌ | U+06D6 | ARABIC SMALL HIGH LIGATURE SAD WITH LAM WITH ALEF MAKSURA |
| ۗ◌ | U+06D7 | ARABIC SMALL HIGH LIGATURE QAF WITH LAM WITH ALEF MAKSURA |
| ۘ◌ | U+06D8 | ARABIC SMALL HIGH MEEM INITIAL FORM |
| ۙ◌ | U+06D9 | ARABIC SMALL HIGH LAM ALEF |
| ۚ◌ | U+06DA | ARABIC SMALL HIGH JEEM |
| ۛ◌ | U+06DB | ARABIC SMALL HIGH THREE DOTS |
| ۜ◌ | U+06DC | ARABIC SMALL HIGH SEEN |
| | U+06DD | ARABIC END OF AYAH |
| ۞ | U+06DE | ARABIC START OF RUB EL HIZB |
| ◌ۡ | U+06E1 | ARABIC SMALL HIGH DOTLESS HEAD OF KHAH |
| ◌ۢ | U+06E2 | ARABIC SMALL HIGH MEEM ISOLATED FORM |
| ◌ۣ | U+06E3 | ARABIC SMALL LOW SEEN |
| ◌ۤ | U+06E4 | ARABIC SMALL HIGH MADDA |
| ۥ | U+06E5 | ARABIC SMALL WAW |
| ۦ | U+06E6 | ARABIC SMALL YEH |
| ◌ۧ | U+06E7 | ARABIC SMALL HIGH YEH |
| ◌ۨ | U+06E8 | ARABIC SMALL HIGH NOON |
| ۩ | U+06E9 | ARABIC PLACE OF SAJDAH |
| ◌۪ | U+06EA | ARABIC EMPTY CENTRE LOW STOP |
| ◌۫ | U+06EB | ARABIC EMPTY CENTRE HIGH STOP |
| ◌ۭ | U+06ED | ARABIC SMALL LOW MEEM |
| ﴾ | U+FD3E | ORNATE LEFT PARENTHESIS |
| ﴿ | U+FD3F | ORNATE RIGHT PARENTHESIS |
| ◌ٓ | U+0653 | ARABIC MADDAH ABOVE |
| ◌ٔ | U+0654 | ARABIC HAMZA ABOVE |
The last two also appear in modern non-Quranic Arabic orthography, but only as part of complete letter forms (آ, أ، ؤ, etc). In the Quran, however, they are used more freely and therefore also appear in Unicode as combining characters. ORNATE LEFT PARENTHESIS and ORNATE RIGHT PARENTHESIS are not used in the Quran per se, but to delimit citations from the Quran in other texts.
Letter binding control
In digital Arabic typesetting, letters change form automatically to correctly bind with adjacent letters. Typing م then ا will produce ما. If you want to show bound forms in isolation, such as ه, you need to be able to manipulate this behavior. This is useful, for example, in pedagogical contexts and in descriptions of Arabic typography or the Arabic writing system.
Unicode has number of control characters to manipulate letter-binding. The most useful is ZERO WIDTH JOINER (U+200D). As its name implies, it takes no space but causes adjacent letter to bind with it. With careful placement of this character, you can show all four forms of a letter they way they are typically displayed in Arabic textbooks:
ه ه ه ه
This line displayed in logical order with control characters visible shows as
ه ه<200d> <200d>ه<200d> <200d>ه
A similar effect can be achieved by the taṭwil/kašīda character ـ (ARABIC TATWEEL U+0640), a horizontal line at the baseline that is normally used to elongate the connection between letter (تطويـــــل). This character can be accessed on the standard Arabic the keyboard layout with Shift+J. The taṭwīl, however, adds a horizontal line, which may or may not be what you want. (Compare ه and هـ).
The ZERO WIDTH JOINER can also be used to disable unwanted ligatures introduced by the typeface. Depending on the typeface, ligatures kick in when two or more specific letters are used next to one another in a given sequence. ZERO WIDTH JOINER between these letters breaks the sequence, negating the ligature, yet allows the letters to connect. To be precise, both letters connect to the intervening ZERO WIDTH JOINER, but visually they will connect to one another. Here are a few examples with words to the right having a ZERO WIDTH JOINER to negate ligatures:
(These are intended to be displayed in the Amiri font, which has a large number of ligatures. If they are displayed in another font with fewer ligatures, the left and right-hand side be may identical for some words.)
| لا | لا |
| لله | لله |
| يحب | يحب |
| محل | محل |
| المسلم | المسلم |
| كما | كما |
There is also a somewhat less useful (for Arabic) ZERO WIDTH NON-JOINER (U+200C) that can be inserted between letters to prevent connections without using a word space: مرحباً.
Transcription
Specialized characters are also needed for Latinate transcription of Arabic. This is primarily done with diacritics that are added to letters from the Latin alphabet: ḥ, ā, š, etc. These are handled in one of two ways in Unicode. The first is the same way as the Arabic vowel diacritics, with combining characters, independent characters that do not take up any horizontal space but add to the preceding letter. Thus, an a directly followed by ◌̄ (COMBINING MACRON U+0304) is displayed as ā. This ā is two separate characters displayed on one and the same letter position. If you place the cursor after this character and hit Backspace, it will only delete the last character in the sequence, i.e., the macron, leaving a lone a.
These are the combining character you need for the system of Arabic transcription most commonly used in Arabic linguistics:
- ◌̄ U+0304 COMBINING MACRON
- ◌̱ U+0331 COMBINING MACRON BELOW
- ◌̇ U+0307 COMBINING DOT ABOVE
- ◌̣ U+0323 COMBINING DOT BELOW
- ◌̌ U+030C COMBINING CARON
As mentioned above, combining characters can be freely combined, to produce, for example, the ḏ̣ used in some transcription systems.
Note that all these combining characters also have “MODIFIER LETTER”-versions that are identical in shape but that are not combining characters. They take up their own horizontal space like normal letters. For example, a followed by ˉ MODIFIER LETTER MACRON U+02C9 is displayed as aˉ.
The second way this type of diacritic is handled in Unicode is in precombined characters. Continuing with our example, there is a precombined ā (LATIN SMALL A WITH MACRON U+0101). Since this is one single character, hitting Backspace after this character deletes the whole thing.
Finally, you also need
- ʾ U+02BE MODIFIER LETTER RIGHT HALF RING
- ʿ U+02BF MODIFIER LETTER LEFT HALF RING
for ʿayn and hamza, and you’re set.
Now, if you type a lot of transcribed text, inserting these characters one by one with manual look-up, copying and pasting, or by typing character codes, is tedious. For typing Arabic transcription, Mamlūk Studies Review provides the Alt-Latin keyboard layout. This layout extends the American QUARTY-layout to include these extra characters with key-combinations. It comes highly recommended. In short it uses
- Alt+a [letter] for letter with macron
- Alt+. [letter] for letter with dot below
- Alt+v [letter] for letter with caron
- Alt+w [letter] for letter with dot above
- Alt+p for ʿ
- Alt+SHIFT+p for ʾ
The system is neatly and clearly explained on the webpage. The layout can be downloaded for Mac or Windows and is easy to install. It can then be accessed with the operating system’s keyboard switching functionality. The characters produced by the Alt-Latin layout are the recombined versions of these letters, i.e., they are not an underlying letter and combining character together.
Vim: See this previous post on how to implement the same functionality internally in Vim, and this post for a more ergonomic variant.
Hyphen in Arabic transcription
My final (mildly pedantic) comment on Arabic transcription is on the use of the hyphen to delineate the definite article al- and other morphemes. The hyphen in transcription is functionally different from the hyphen used in normal text. In normal text, the hyphen (HYPHEN MINUS U+002D) allows for line-breaks and is used for compound words or inserted to break up long words at the end of a line in justified text (text with a straight right-hand margin). It is entered by pressing the --key on the keyboard. Using this normal hyphen in transcription may produce line-breaks within transcribed Arabic words. The problem with this is that the hyphen reads as being inserted for line-breaking rather than as part of the word. The following two examples of this (from Versteegh 1983: 140 and Suleiman 2011: 20):
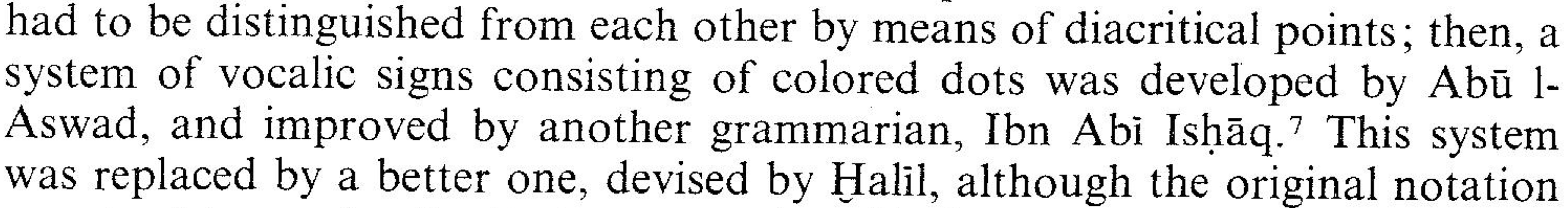
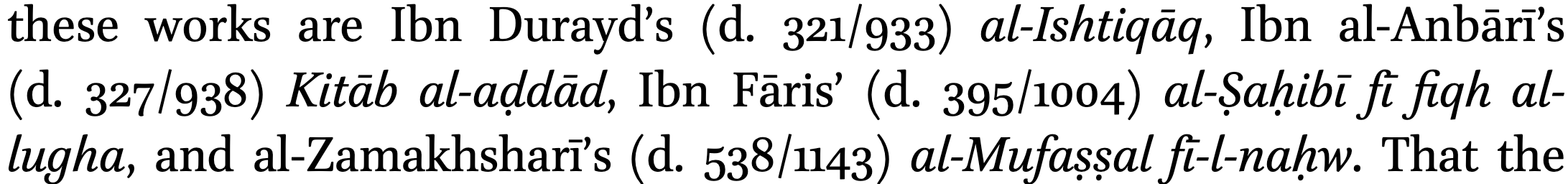
To avoid this, you can instead use ‑ (NON-BREAKING - U+2011). This character is visually identical to the normal hyphen but, as the name suggest, does not allow for line-breaking and ensures that the entire transcribed word is always on the same line.
Conclusion
Unicode: it’s pretty awesome.
References
Hallberg, A. (2016). Case endings in Spoken Standard Arabic: Statistics, norms, and diversity in unscripted formal speech [Doctoral dissertation, Lund University]. https://lup.lub.lu.se/record/8524489
Suleiman, Y. (2011). Ideology, grammar-making and the standardization of Arabic. In B. Orfali (Ed.), In the shadow of Arabic: The centrality of language to Arabic culture. Brill. https://doi.org/10.1163/9789004216136_002
The Unicode Standard: Version 12.0 — core specifications. (2019). Unicode Consortium. http://www.unicode.org/versions/Unicode12.0.0/UnicodeStandard-12.0.pdf
Versteegh, K. (1983). Arabic grammar and corruption of speech. Al-Abhath, 31, 139–160.